Related Projects

Why Should I Trust You?": Explaining the Predictions of Any Classifier"
Institutions: U of Washington
Authors: M. T. Ribeiro, S. Singh, S. and C. Guestrin
Publication:
Why Should I Trust You?: Explaining the Predictions of Any Classifier, KDD, 2016
Source Code:
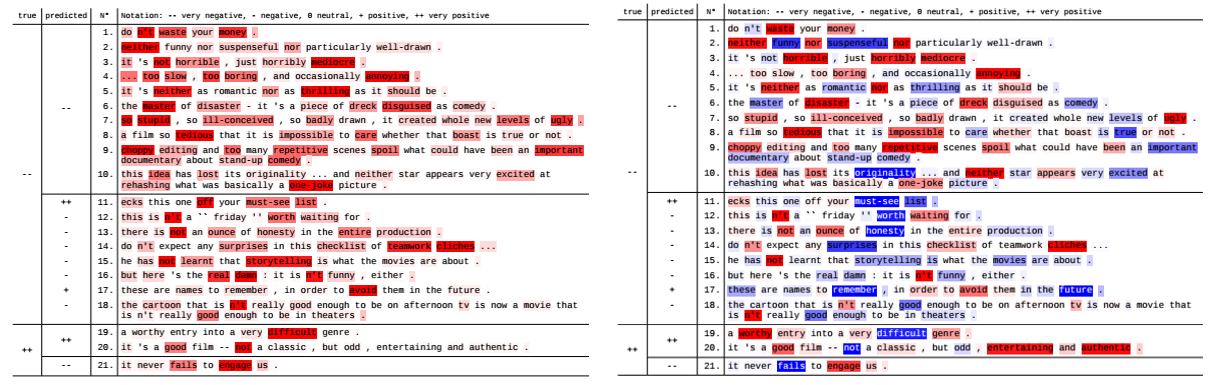
Explaining Recurrent Neural Network Predictions in Sentiment Analysis
Institutions: Fraunhofer, TU Berlin, Korea University, Max
Authors: L. Arras, G. Montavon, K-R. Müller and W. Samek
Publication:
Explaining Recurrent Neural Network Predictions in Sentiment Analysis, EMNLP, 2017
Source Code:

Interpretable classifiers using rules and Bayesian analysis: Building a better stroke prediction model
Institutions: MIT, U of Washington, Columbia
Authors: B. Letham, C. Rudin, T. McCormick and D. Madigan
Publication:
Source Code:
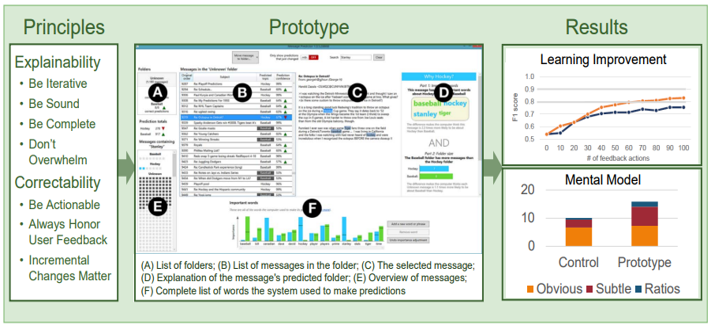
Principles of Explanatory Debugging to Personalize Interactive Machine Learning
Institutions: Oregon State, City University London
Authors: T. Kulesza, M. Burnett, W-K. Wong and S. Stumpf
Publication:
Principles of Explanatory Debugging to Personalize Interactive Machine Learning, IUI, 2015
Source Code: